Artificial Intelligence (AI) is getting infused into every sphere of our life. We find AI-powered smartphone cameras, devices, and voice assistants like Cortana, Alexa, Bixby, and various other alternatives. AI and Machine Learning (ML) is used to predict thing based on past patterns. In every industry, there are use cases related to AI and ML which can help improve people's lives in one way or the others.
One such area which is of keen interest is software developers. There are various studies done across the globe to improve developer productivity. Software developers spend a lot of time writing code and looking for information over the internet. We use things like code editors such as Notepad++, Sublime, Visual Studio Code, a full-blown integrated development environment such as Visual Studio Code, IntelliJ, PyCharm, Goland, Eclipse, Rider, etc., database connectivity tools, and many other things to get our work done. This involves context-switching between different tools depending on the type of application and the programming language or backend databases used for the application development.
AI-powered assistant for developers
Many of the code snippets that we write are following a specific pattern. Some of the common examples are listed below
Query database table and fetch top 100 Orders, sort by highest order value
Perform sentiment analysis on a tweet / social media post
Make an API call to query some data
Write a function to find the average size of the basket from a given carts
These are just a few examples. But you can get a sense of the pattern that is being used. What varies is the programming language used and the syntax of the language. Nowadays it is possible to use Natural Language Processing (NLP) to specify the intent of what the code intends to do and let AI generate the code.
One such tool I came across is called tabnine. The tagline for tabnine says that it is an AI assistant for software developers. It helps developers to write code faster. It has two modes of operation. First is the single line mode where it recommends code for one single line. Ans second is the whole function code.
It integrates with the most common Integrated Development Environments (IDE) and supports most of modern-day programming languages and frameworks. The screenshots below list the IDEs and programming languages that it supports.
Refer to the install section to get the most updated list of IDEs and programming languages. If the language you are using or the IDE you are using is not on the list, most probably you are not working with a modern tech stack :)
My experience with Tabnine
I used Tabnine with my favorite code editor Visual Studio Code. I used it to generate C# code, document the project using Markdown files, and to write Powershell scripts. It was quite accurate in terms of its suggestions and recommendations with an accuracy rate of about 75-80%. It saved me quite a lot of time while writing the docs for a project.
Although Markdown and Powershell are not listed in the supported languages, tabnine did a fantastic job in terms of proving context-aware recommendations.
I shared my experience of using Tabnine in a YouTube video.
Summary / Conclusion
Personally, I found Tabnine very useful. It avoided the context switching for me to look for information. It helped me to generate code faster. Documenting the code or project with markdown files was a breeze saving me at least 70% of the typing efforts.
I think a tool like Tabnine can be very handy when we are learning a new programming language. It can help us quickly understand code syntax and best practices. The machine learning model used to train the assistant can scan different types of repositories within the organization as well as public repositories. This can help to implement best practices.
Hope you find this useful. I would love to hear about your experience.
Until next time, Code with Passion and Strive for Excellence.
Nowadays modern cloud-native applications are developed and deployed at a rapid scale and pace. The legacy techniques used for upgrading applications and services are no longer relevant. We want to give the best user experience to end users. One of the things which are gaining popularity and is already a mainstream technique is progressive delivery. This allows us to upgrade the application version in a progressive manner by reducing the blast radius. In this post, we will look at how to achieve zero downtime deployment using the Rolling Update strategy with Kubernetes.
Quick overview of the rolling update strategy
The rolling update strategy allows applications with multiple instances or replicas to upgrade from one version to another in a controlled manner. Instead of upgrading all the replicas together, this strategy applies changes in batches and replaces the older version with a new one. As a result of this, the application can continue to run with the reduced number of instances while the upgrade is progressing.
One of the pre-requisite for implementing a rolling update strategy is that the application needs to have multiple replicas or instances running. If there is only a single instance of the application, there will be a slight downtime. Kubernetes supports the rolling update strategy natively. We do not need any additional things to implement it with Kubernetes. When we use Kubernetes Deployment to deploy our pods, the rolling update is the default strategy.
If you have been using Kubernetes deployments, you would have unknowingly used the rolling update strategy when upgrading the application version.
Use the Rolling update strategy for zero downtime deployment
If we don't override any settings related to rolling updates, by default Kubernetes will apply 25% MaxSurge and 25% MaxUnavailable settings. What this means is that at the time of the upgrade maximum of 25% of the replicas will be added. Same way, when the old version of the replica is replaced with the new one, a maximum of 25% would be replaced at a time.
By doing this, it ensures that there are 80% of replicas in working condition during the upgrade process and the end users are not impacted. If we have exposed the deployment outside of the Kubernetes cluster using a Service, then the LoadBalancer will route the traffic accordingly between the new and older versions.
Youtube video demo
Refer to the YouTube video to see this in action.
Other alternatives to Rolling Update Strategy
There are other alternatives to the rolling update strategy. Modern-day cloud-native applications support advanced deployment strategies or techniques such as Blue-Green deployment or Canary deployment which also allow zero downtime deployment with progressive delivery. Refer to the links to watch YouTube videos on my channel to understand how these can be applied to your Kubernetes applications.
Conclusion
Gone are the days of bringing down servers and applications to upgrade them. With the cloud, we can easily upgrade applications and services with minimal impact on end users. Use modern techniques such as rolling update, Blue Green deployment or Canary deployment to achieve 100% availability for your application.
Until next time, Code with Passion and Strive for Excellence.
A few years back Heroku published a set of guidelines for building and deploying applications which became known as 12 Factor App. These are guiding principles for developing, operating and deploying Web apps or software-as-a-service (SaaS). Over a period of time, as cloud adoption increased and microservices became popular there are additional factors which got added. We also saw changes in the application integration space with more real-time processing gaining popularity. We now have event driven microservices which empower organisations to leverage data to get more value using event driven architecture.
15 Factor Apps series
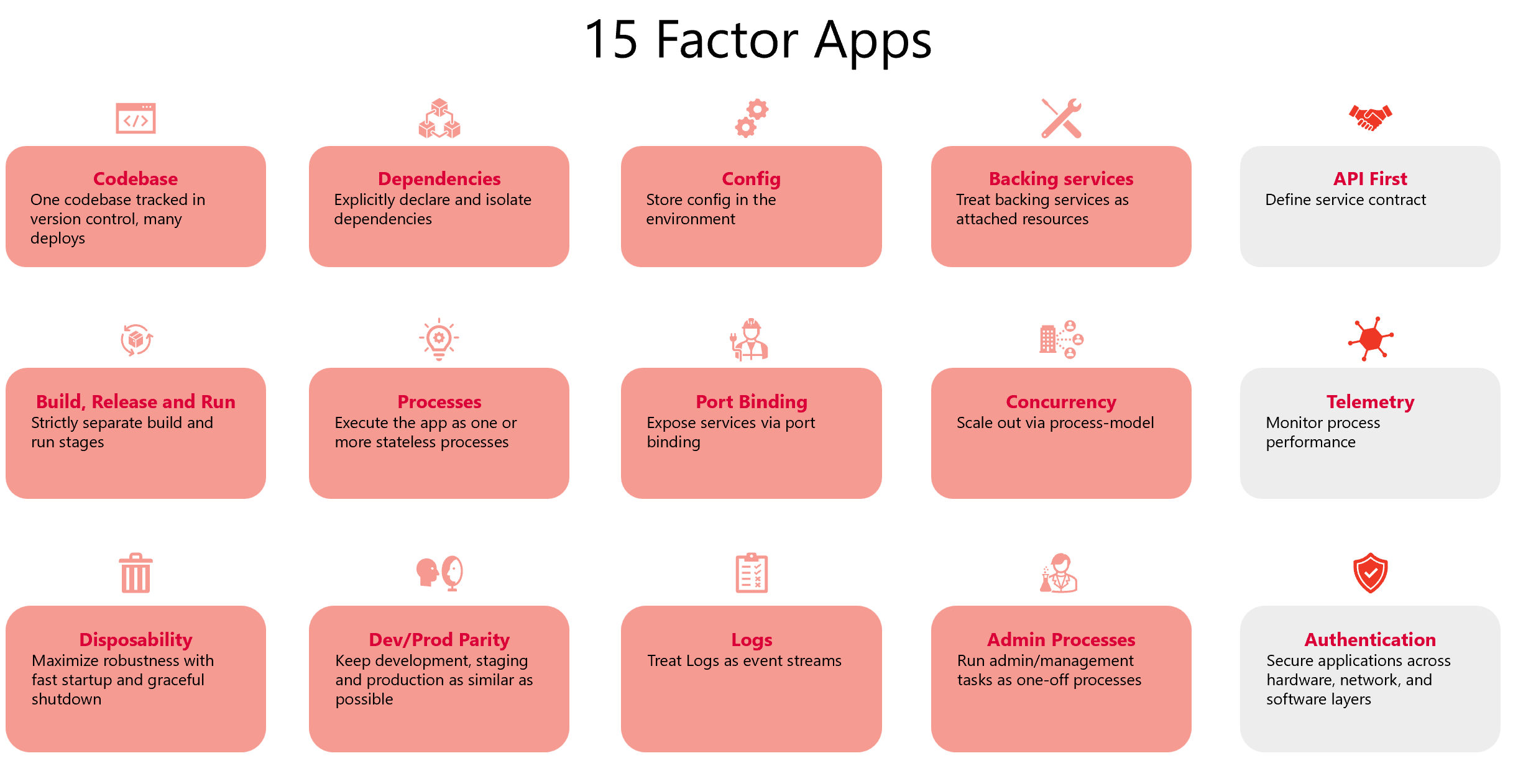
In order to understand the 15 factors better, I am creating this series of YouTube videos. We will cover all the 15 factors in different parts. Below is the picture showing the initial 12 factors as described in the 12Factor.net and then we also have the next picture showing the additional 3 factors as part of the 15 factors.
Here is a list of 15 Factors which help to make the modern cloud-native applications highly scalable, resilient and portable:
Codebase - one codebase tracked in version control, many deploys
Dependencies - Explicitly declare and isolate dependencies
Config - store config in environment
Backing services - treat backing service as an attached resource
Build, release and run - strictly separate build and run phases
Processes - execute app as one or more stateless processes
Port binding - expose services via port binding
Concurrency - scale-out via process model
Disposability - maximize robustness with fast startup and graceful shutdown
Dev/Prod parity - keep development, staging and production as similar as possible
Logs - treat logs as stream of events
Admin processes - Run admin/management tasks as one-off process
API first - define service contract
Telemetry - monitor process performance
Authentication - secure applications across hardware, network and software layers
Youtube videos
Below is the list of videos covering each of these factors
Blue-Green deployment is a strategy to achieve zero-downtime deployment. With cloud-native applications, it is common practice to reduce downtime when upgrading the application version. Due to the ease with which we can provision new infrastructure on the cloud, it becomes easier to adopt new ways of improving the deployment.
Blue Green deployment definition
In this post, we will look at how to use Blue-Green deployment with Kubernetes. One of the best places to look for definition is the glossary of terms provided by Cloud Native Computing Foundation (CNCF). The CNCF defines Blue Green deployment as
"A strategy for updating running computer systems with minimal downtime. The operator maintains two environments, dubbed “blue” and “green”. One serves production traffic (the version all users are currently using), whilst the other is updated. Once testing has concluded on the non-active (green) environment, production traffic is switched over (often via the use of a load balancer)."
The main point here is two identical environments named blue and green and the traffic switching using load balancer. Lets see how this can be applied to the Kubernetes environment.
How to perform Kubernetes Blue Green Deployment
We start by creating two versions of the application. Let's say V1 which is deployed to the live environment. This forms our Blue environment. To keep things simple, I have created a simple ASP.Net Core application. It is packaged into a Docker image with two tags. One tag has Blue background and will be used to deploy to the Blue environment. The other container image with green tag will be used to deploy to the Green environment. The two docker container images are published to Dockerhub as
nileshgule/blue-green-demo:blue
nileshgule/blue-green-demo:green
Step 1 : Setup Blue environment
Once the container images are pushed to the container registry, we can use Kubernetes Deployment to deploy to the Kubernetes cluster. We create a blue-deployment using the image tagged as blue. The Kubernetes deployment will internally create a replicaset and related pod. In the pod deployment template we set the label as app: blue.
The deployment is exposed outside the Kubernetes cluster using a Kubernetes service of the type loadbalancer. The service uses the selector with app: blue value.
Browse the public IP of the loadbalancer service and we will be presented with the web page with Blue background.
Step 2: Setup Green environment
The second step of the Blue-Green deployment is to create the Green environment. This is done by creating a 2nd Kuberentes deployment using the image nileshgule/blue-green-demo:green tag. We also set the label for the deployment as app: green. The rest of the attributes in the manifest file are almost same as the blue deployment. After applying the Green deployment, the service is still serving 100% traffic to Blue environment. We can perform test on the next version or release of the application which is deployed to the green environment. If the tests are successful, we can switch the traffic to green environment.
Step 3: Route traffic to Green environment
The final step in the Blue-Green deployment is to switch the traffic to the Green environment. We can do this by editing the service manifest. We update the selector to select the pods with app: green label. Apply this change to the Kubernetes service. All the traffic is now redirected to the Green environment.
Note that the Blue environment is still there, but the active or live traffic is served by the green environment. If there is any problem with the Green environment, we can change the selector in the service again to point back to the Blue environment quickly allowing us to revert the changes with minimal impact on the end users.
Youtube video
The steps explained in this blog post are demonstrated in the Youtube video in detail. Watch the video for a live demo and feel free to provide feedback in the video comments.
Conclusion
It is very easy to use the Blue-Green deployment strategy with Kubernetes using Service. This strategy is quite useful to reduce the downtime for stateless applications. Stateful applications are a bit more involved. This reduces the risk during application upgrades. By having a standby environment we can easily fallback to an older version with no downtime. Hope you found this useful.
Until next time, Code with Passion and Strive for Excellence.
Kubernetes is the de-facto standard for orchestrating containers. If you are working on a daily basis with Kubernetes, you are most likely using the kubectl to interact with the Kubernetes cluster for performing different operations like listing pods, checking for deployments, viewing logs etc. Working with kubectl using a terminal is the most common approach in such a scenario.
Earlier I had demonstrated how to use two power tools kubectx and kubens. In this post, we will look at how to give kubectl a huge productivity boost by using programmatically generated aliases.
A quick word on the alias
If you come from a scripting background with experience in bash or shell scripting or even Powershell scripts, you might be familiar with aliases. These are like shortcuts that we can add to the terminal session to execute a command or piece of code. One of the most commonly used alias while working with kubectl is k. Instead of typing kubectl every time, most people create an alias with k and we can replace/substitute kubectl with k.
We can persist the aliases across sessions and store them permanently. In the case of bash aliases on Linux or Unix systems, mostly these are stored in the .bashrc profile file under the home directory of the user. The same thing can be done on a Windows environment by creating a function as an alias in a PowerShell profile document.
Need for kubectl aliases
Now that we understand a bit about aliases, let us see how we can use them with Kubernetes and kubectl to be specific. Kubernetes has various objects like Pods, Deployments, Replicasets, Nodes, Endpoints, PersistentVolume, PersistentVolumeClaims etc. Each of these objects has support for different operations like create, update, delete, edit, get. Along with the different types of operations, there are also different flags that can be used while working with these objects using kubectl like -A or --all for listing objects from all namespaces.
Kubectl also supports displaying information in different formats like JSON or YAML. In order to improve efficiency and productivity while working with kubectl, we can alias the commonly used commands as shown below:
alias kg="k get"
alias kgpo="kg po" or alias kgpo="kg pods"
alias kgno="kg no" or alias kgno="kg nodes"
alias kd="k describe"
alias kaf="k apply -f"
alias kdf="k delete -f"
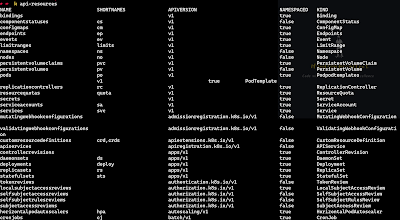
Note that some Kubernetes objects have short forms like po for pods and no for nodes. We can get the list of resources supported by Kubernetes along with their short names using the following command
kubectl api-resources
The above screenshot shows a partial list of resources, their short names, API versions etc.
If we were to create aliases for each of the resources and different operations supported for that resources, it will be a very time consuming and cumbersome process. This is where a smart guy names Ahmet Alp Balkan came up with a programmatic way to generate aliases for kubectl.
kubectl-aliases
The Github repository contains the list of over 800 aliases that are programmatically generated. It also contains instructions about how to set up these aliases. We need to download the file and source it in our bash profile which makes these aliases available for us to use with the terminal session.
There is a set of conventions followed while naming or generating these aliases.
k = kubectl
sys = --namespace kube-system
commands
g = get
d = describe
rm = delete
a : apply -f
ak : apply -k
k : kustomize
ex : exec -t -t
lo : logs -f
resources
po = pod
dep = deployment
ing = ingress
svc = service
cm = configmap
sec = secret
ns = namespace
no = node
flags
output formats : oyaml, ojson, owide
all : -all or --all-namespaces depending on command
sl : --show-labels
w : -w/--watch
value flags : should be at the end
n = -n/--namespace
f = -f/--filename
l = -l/--selector
Using these conventions it is quite convenient to work with kubectl. This reduces typing errors and improves our efficiency greatly. Here are a few examples
k get pods --> kgpo
k get pods --all-namespaces --> kgpoall
k get pods -n kube-system --> ksyspo
k get pods -o yaml -> kgpooyaml
k get configmaps -n keda --> kgcmn keda
If you are on Windows machine, you need not be left behind. There is a PowerShell version of these aliases. Here is the link to the Github repository created by Shanoor.
Youtube video
I created a short video demonstrating these in much more detail. Catch all the action in the below Youtube video.
Conclusion
We all want to improve our daily ways of working. I am sure you will benefit from this little tip if you are a regular user of Kubectl. Hopefully in your role as a developer or DevOps engineer or SRE role you find this useful. Do let me know in the comments of this post or in the Youtube video if you have any feedback.
Until next time, Code with Passion and Strive for Excellence.
The new year started on a happy note for me. A few days back, I cleared the Certified Kubernetes Application Developer (CKAD) certification. This was on the second attempt that I managed to clear the exam. It is the best online certification exam I have answered so far. This post is about my experience with the exam and how to prepare for it. I also share some information that might be helpful during the exam itself.
Exam Curriculum
The exam is completely hands on. There are no multiple choice questions. We are given a set of 6 different Kubernetes clusters. Each cluster has a different configuration and the questions are related to designing and developing cloud native applications in the Kubernetes environment. There are five different broad areas which are assessed as shown below. These include
Application Design and Build 20%
Application Deployment 20%
Application Observability and Maintenance 15%
Application Environment, Configuration and Security 25%
Services & Networking 20%
The exam is conducted by Linux Foundation in collaboration with Cloud Native Computing Foundation (CNCF). You can find out more about the exam on the Linux Foundation training website.
The duration of the test is 2 hours with 66% as the minimum passing score. The certificate is valid for 3 years. In case you are not able to clear on the first attempt, you get 1 free retake.
References for exam preparation
I like to use multiple resources while preparing for any certifications. For CKAD as well I referred to multiple sources of information. Here is a quick list of different references I used.
Kubernetes docs
We are allowed to refer to the Kubernetes docs during the exam. It is like an open book test. The following links are helpful for getting started with Kubernetes and understanding the different concepts.
Along with the Kubernetes docs, I supplemented the knowledge by registering for the eLearning course. There are many courses available online. Almost every eLearning platform will have one or more course related to the CKA exam preparation. Some also offer mock test. I took the CKAD exam plus the Kubernetes fundamentals bundle from Linux foundation.
I liked the details and the depth this course covers the contents. There are hands on labs or mini tests after every major topic. The course is filled with lots of gems in the form of tips and tricks related to the actual exam.
Github Repos
Here is a list of Github repositories I found useful
CKAD practical challenge series - https://codeburst.io/kubernetes-ckad-weekly-challenges-overview-and-tips-7282b36a2681Tips
Watch out for discounts
You will find discounts during Black Friday, Cyber Monday, Christmas, New Year, Diwali, Eid etc. Make use of these discounts on learning courses as well as the actual test.
Learn Imperative commands
Due to the time limit of 2 hours, you need to be quick in finishing the tasks related to completing the exam. While you can copy and paste yaml from the Kubernetes documentation, editing it could take some time. The test will have specific requirements like naming Kubernetes objects with specific names and deploying them to a specific namespace. Usually, Kubernetes docs will deploy the objects in default namespace. It will save you quite some time if you know how to work with imperative commands. The output of these commands can be piped to yaml files and then you can make the required modifications instead of handcrafting the complete yaml from scratch.
Compared to CKA exam, I found the questions in CKAD to be lengthy. There are more subtasks for each question. You end up solving more subtasks and you need to be really fast.
Learn basic vi or nano editor commands
The test environment is Linux based. If you are coming from Windows background like me, you need to be familiar with vi or nano code editors. Be familiar with editing files and command like deleting lines of code, navigating to specific lines, updating a word, saving files etc.
Here is a handy cheatsheet I found to work with the vi editor more effectively.
Practice, Practice, practice
Whoever has cleared the CKA, CKAD or CKS exams will tell you that practice is the most important part of exam preparation. If you don't know how to work with the Kubernetes resources or objects using kubectl, there is no way you are going to clear this test. There could be multiple ways of achieving the same task. You need to find the one which is the most time efficient.
Bookmark specific links
Bookmarking the links from Kubernetes documentation is helpful to find the resource quickly. Instead of bookmarking the top level pages, I recommend bookmarking specific sections to avoid scrolling through the lengthy page looking for information.
Practice exam
If you book the Kubernetes related certification exam after June 2021, you will have access to the practice exam from Killer.sh. This exam gives you two attempts at the same test. The environment is available for 36 hours and answers along with a detailed explanation of the steps is provided to help you prepare better for real test.
Tips during the exam
Use external monitor (recommended), minimize screen switching
External keyboard and mouse can be used
Enable kubectl auto completions
create aliases (before starting test)
Update vimrc / editor profile
Time management
use imperative commands (huge time saver)
use copy feature instead of typing
use the notepad feature to make quick notes
flag questions for review
don't spend too much time on a single question (avg 5-6 mins)
verify solution after task completion
Aliases in bash profile
I added the following aliases in the bash profile to reduce typing kubectl commands
alias cls=clear
alias kg='k get'
alias kgpo='kg po'
alias kgno='kg no'
alias kdes='k describe'
alias kaf='k apply -f'
alias kdf='k delete -f'
Along with these aliases, I had also exported to handy commands
export do='--dry-run=client -o yaml'
export fg='--force --grace-period=0'
vi editor settings
Last but not the least, I also updated the settings for vi editor so that text can be aligned/indented properly when we tab in the editor. This also helps when we copy and paste the code snippets from Kubernetes docs.
set tabstop=2
set shiftwidth=2
set expandtab
Youtube video
All the topics mentioned in this post are explained in more detail in the Youtube video.
Conclusion
CKAD certification is meant to gauge the skills of Kubernetes developers. If you do not know how to build and deploy cloud-native applications which are deployed on the Kubernetes cluster, this certification is not for you. Practice well before taking the exam. There are 17 questions with different weights. Hope this post is helpful for those preparing for the exam in future.
Until next time, Code with Passion and Strive for Excellence.
My views about Software Design and Architecture around Microsoft DotNet, Big Data and Cloud Computing. Strong believer of developer community, passionate about Software development and Architecture. Always committed to excellence in technology.
About me
Nilesh Gule
Microsoft Azure MVP | Blogger | Speaker | Technical Evangelist | Cricket fan